Ibex is a new table focused language for analysis of tabular data and time-series. Its goal is to combine the conciseness of data.table with speed, obtained by native code generation, a fast interpreter and lots of attention for efficient algorithms and code. It aims to make exploratory queries quick to write and fast to execute. The goal is to make data analysis feel smooth and fast. A demo of a quant pipeline gives an idea of what is possible.
Since my previous post on Ibex a lot has happened. Ibex gained useful features, speed and benchmarks (these numbers are before multithreading support) and cross platform binaries. The new features are
- Rich join support, with a basic approach to join planning.
- Vectorization and efficient algorithms of common table operations.
- Date and Timestamps are efficiently stored as signed counts since epoch.
- Time Series support: windowing, rolling, grouped rolling, resampling, as-of joins.
- Fast, vectorized RNG using Zorro (
xoshiro256++based). Purpose-built for Ibex and split off. - Multithreading in active development but for OHLCV analysis I have some promising results already. However, I only looked at this narrow use case of writing.
- Some integration work for Python and R but still alpha.
- Plugins for I/O and data analytics.
- Some exploration in how an effect system can work for Ibex. The syntax supports it but the Ibex optimizer doesn’t use the information yet. Long term goal is to allow Ibex to efficiently use code in plugins, for example by reordering function calls if it can be proven this is correct based on the given effects.
Ergonomics
I started working on Ibex with a focus on ergonomics. It should be easy to write quick analysis without too much special characters or using the shift key. OHLCV looks like this:
ticks[ select {
open = first(price),
high = max(price),
low = min(price),
close = last(price),
volume_sum = sum(volume) },
by symbol,
resample 10s,
order symbol ]Ticks is a table (TimeFrame) with columns timestamp, symbol, price and volume. The expression selects the data it wants in the select clause, by symbol instructs Ibex to group the rows by symbol, resample 10s uses a duration literal to resample the data in 10 second long buckets and the final clause orders by symbol. The ordering by timestamp is implicit. Short, sweet and easy to write. The code is succinct but there is no need to do any code golf to get to that low count. select can be omitted if you want. The syntax borrows heavily from both R’s data.table and SQL keywords. Compared to libraries such as Polars, Pandas and data.table, there is no need to quote column names. The Ibex syntax is specialized for tables and will look up names in the table context first, then in the outer scope. Compared to SQL, the order of the clauses is free so it is possible to write queries in the order that feels natural for the problem at hand. Of course, I’m biased but I would use the Ibex syntax for its convenience alone.
Joins
Joins are easy to write as well, and quite fast. Using the nycflights13 data set we can get the name of the carrier of the flight using a join and then do a group by and count. Very little boilerplate required. Every word or symbol in the expression is contributing something meaningful to the semantics of the query.
$> (flights join airlines on carrier)[flights = count(), by name, order flights desc]
rows: 16
+----------------------------+---------+
| name | flights |
+----------------------------+---------+
| "United Air Lines Inc." | 58665 |
| "JetBlue Airways" | 54635 |
| "ExpressJet Airlines Inc." | 54173 |
| "Delta Air Lines Inc." | 48110 |
| "American Airlines Inc." | 32729 |
| "Envoy Air" | 26397 |
| "US Airways Inc." | 20536 |
| "Endeavor Air Inc." | 18460 |
| "Southwest Airlines Co." | 12275 |
| "Virgin America" | 5162 |
+----------------------------+---------+
... (6 more rows)
time: 10.246 ms
TimeFrame
The TimeFrame is a unique feature to Ibex. A TimeFrame is like a regular DataFrame that is always has one chosen timestamp column as the final in an ordering. It is what makes the resample keyword in the snippet above work. This simplifies writing time series analysis such as windowing and resampling and reduces the likelihood of errors.
Performance
Being convenient might not be enough to convince everybody though. I have done some benchmarking and am still doing more. Ibex performs very well on one core but lags more mature engines when the core count goes up. Often, on a single core it is competitive with multithreaded Polars and now that multithreaded Ibex is in development, I’m confident that it will be be beating Polars, Clickhouse and DuckDB in many real world use cases in the coming months. Fully replicating the PDS benchmark ran by Polars is on the short term roadmap. An excerpt from the in-memory benchmarks, single threaded Ibex against the multithreaded competition (8 cores) on 32 million rows:
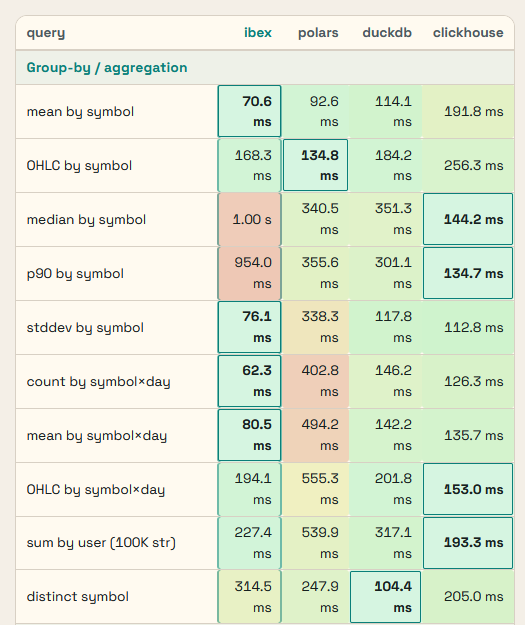
Deep dives in why Ibex performs as well as it does will be published in follow-up blog posts.
Plugins and interop
Ibex supports plugins to allow interop and more general programming. Through these plugins Ibex can read and write parquet and CSV. For data analysis, there is a k-means, pca plugin. For generating some fake data, you can use the data_gen plugin:
$> let ticks = as_timeframe(gen_ticks(1000000), "timestamp")
time: 16.968 ms
$> ticks[{O = first(price), C = last(price), V = sum(volume)}, by symbol, resample 60s]
rows: 50025
+-------------------------------+--------+----------+----------+--------+
| timestamp | symbol | O | C | V |
+-------------------------------+--------+----------+----------+--------+
| 2026-07-30 20:11:00.000000000 | "AAPL" | 100.9047 | 96.22321 | 89611 |
| 2026-07-30 20:11:00.000000000 | "MSFT" | 100.7327 | 95.66605 | 65025 |
| 2026-07-30 20:11:00.000000000 | "GOOG" | 100.7039 | 96.51451 | 90992 |
| 2026-07-30 20:12:00.000000000 | "AAPL" | 97.07213 | 100.0082 | 116929 |
| 2026-07-30 20:12:00.000000000 | "GOOG" | 97.45437 | 99.38058 | 129402 |
| 2026-07-30 20:12:00.000000000 | "MSFT" | 97.56397 | 99.57706 | 117411 |
| 2026-07-30 20:13:00.000000000 | "MSFT" | 100.8203 | 95.96139 | 139896 |
| 2026-07-30 20:13:00.000000000 | "AAPL" | 101.1467 | 95.22558 | 75865 |
| 2026-07-30 20:13:00.000000000 | "GOOG" | 100.9836 | 95.42231 | 99968 |
| 2026-07-30 20:14:00.000000000 | "GOOG" | 94.88445 | 91.22123 | 144432 |
+-------------------------------+--------+----------+----------+--------+
... (50015 more rows)
time: 18.779 ms
Roadmap
The important table operations have been implemented and perform quite well on a single core. Improving multithreading support and further development of the plugins. My early experiments have shown that on the small PDS set (SF-1) Ibex is competitive on a single core, it loses when core counts go up. Making Ibex work efficiently on huge machines will take some effort, probably a lot.
Conclusion
Ibex is an ergonomic and fast alternative for the well known analytical data processors such as Polars and DuckDB. In my benchmarking it beats the alternatives on a single core and the syntax is both easy to read and write. Efficient threading is actively being worked on and initial experiments suggest that the single core performance holds up in a multithreaded setting.
The Ibex website shows you how to get started.